
語言: 中文 | English
我叫做 Matt, 是一名菜鳥工程師.
目前我是一名AI工程師,擅長 大語言模型(LLM) 與 語音AI。
經歷
National Pintung University, Hakka speech recognition Project (July 2022 - July 2023)
- Kaldi
- Espnet
- 語音辨識

Kaldi, TDNN-F 演算法
最初我嘗試使用現成語音訓練工具 ‘Kaldi’進行建模
並使用TDNN-F演算法作為訓練方法
TDNN-F算法的優點:在訓練時,模型會參考前後文進行學習,從而選擇出最有可能的答案。此舉使得模型在選字時,會更符合語者當下的語境、語意。
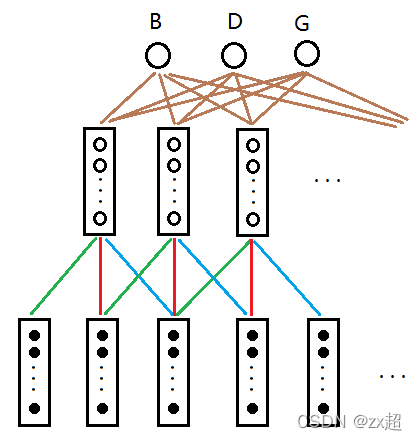
Espnet, End-to-End and Contextual-Block-Conformer
後期改用語音訓練工具 ‘Espnet’進行建模
不同於‘Kaldi’的’GMM & HMM’架構,‘Espnet’使用’End to End’架構
優點: 利用神經網路,模型可以自行學習知識,而不需要對模型的每個步驟進行優化。
缺點: 在模型結果不如預期時,能調整的部分變少了;因此須確保訓練資料足夠充足,才可以考慮使用End to End架構。


國立陽明交通大學, Speech AI Research Center(SARC) (July 2023 - March 2024)
- 大語言模型
- 資料預處理
- 伺服器主機維護
- GitLab 維護
與 TAIDE 合作
TAIDE計畫,是由「中央大學 蔡宗翰教授」與「臺灣大學 李宏毅教授」等學界名師主導的國科會計畫。
TAIDE致力於打造一個台灣專用的ChatGPT。
SARC對TAIDE模型進行本土化調適,於2023/9開始正式合作,並於2023/11調適出「台語、客語」大語言模型,並於同一時間上架至TAIDE公測平台,提供給TAIDE團隊與其合作夥伴使用。
更多有關TAIDE


以下是建模大語言模型時的詳細步驟
- 選定基礎模型
- 對編碼器(Tokenizer)進行目標語言做擴增進行優化。
- 在這個階段讓模型閱讀大量目標語言的文章,以此培養模型對新語言的語感。
- 學會新語言怎麼說以後,就可以訓練模型如何回答用目標語言提出的問題,此處輸入大量問答題,訓練模型回答不同問題。
- 新的模型出爐
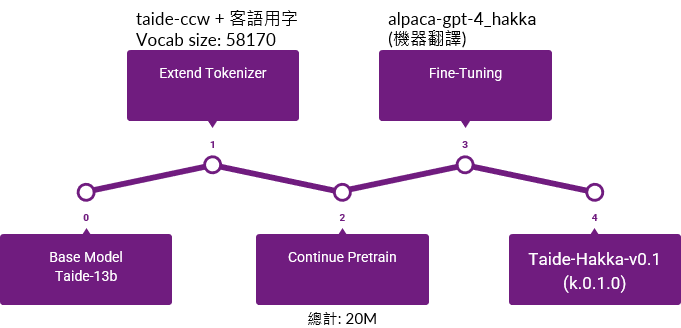
與群聯電子(PHISON) 合作 (aiDAPTIV+)
設備維護
- 管理Linux伺服器的所有使用者與其權限
- 維護Linux伺服器的軟體系統環境
- 維護Linux伺服器硬體
- 設定Linux伺服器網路環境與跨主機串接、NAS設定
DLink AI Engineer (6/11~now)
- 語音辨識
- 大語言模型
- AI翻譯器
中文+台語 Whisper Fine-Tune (6/11~now, long tern job)
將大量從 YouTube 獲取的資料進行整理,儘管大多數資料還是有標註不準確的問題。
使用總共大約3000小時的語料(non proof data)進行 Full Fine-Tune.
最終正確辨識率大約為76%,後續擴增、清理資料後可以繼續提升辨識率.
嘗試使用模型進行清理所有non-proof-data
在模型辨識的結果中,cer + confidence*-100的分數超過閥值時,就暫時標記為危害資料
針對這批資料,在進行二次掃描與人工校對,完成資料的清洗
LLM 評估 (7/12~7/30)
搭建 Ollama 平台於工作站。
使用 IFEval 來評估模型對與指令順從度的測驗。
也可以參考文章,我有針對這篇論文做一些簡述。

Retrieval-Augmented Generation, RAG檢索 (7/30~8/29)
利用 RAG & Prompt Engineering 技術,對LLM進行客製化,為現今成本最低的調整模型方法。
將未經過fine-tune的LLM,調整為行事曆查詢器,並對行程總結。

BLE Socket server (9/2~9/18)
利用簡單的socket server,與遠端裝置建立連線,傳送一段音檔(raw audio)
並在遠端裝置中,將接收到的音檔,投射至藍芽裝置進行播放
在此項專案中,於遠端裝置特別使用了pulseaudio對藍芽裝置建立虛擬音效卡,才得以順利播放音檔
Retrieval based Voice Conversion, AI Song Conver (10/24~now)
搜集一個使用者的聲音(至少3分鐘人聲),讓模型進行聲音檢索(Retrieval),在預訓練模型中找到與使用者最相似的聲音做為訓練目標
模型fine-tune完成後,將一段參考音檔給模型聽過後,模型會嘗試使用使用者的聲音,發出參考音檔的內容。
實際範例: 紫砂歐那
使用者
參考音檔
輸出