
Language: 中文 | English
Update at 8/15, if you are looking for my newest info, check Mandarin
My name is Matt, I’m a new born software engineer.
Now I am an AI Engineer. Expert at Large Language Model and Speech AI.
Experience
National Pintung University, Hakka speech recognition Project (July 2022 - July 2023)
- Kaldi
- Espnet
- Speech Recognition

Kaldi, TDNN-F algorithm
At the very first time, I tried using the existing tool ‘Kaldi’ to modeling my ASR model. I used TDNN-F algorithm as our approach
Benefit of TDNN-F : Model will reference content of the input while training, then pick the most possible answer.
This approach enables the model to choose characters that better fit the speaker’s current context and semantics when making selections.
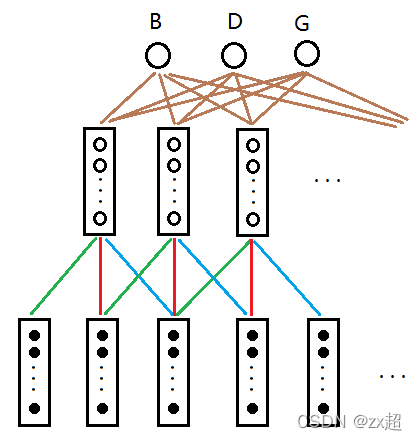
Espnet, End-to-End and Contextual-Block-Conformer
In the later stages, the modeling was switched to another speech training tool ‘Espnet’. Unlike the ‘GMM & HMM’ architecture of ‘Kaldi’, ‘Espnet’ employs an ‘End to End’ framework.
Advantages: Utilizing neural networks, the model can autonomously learn knowledge without the need for optimization at each step of the model.
Disadvantages: When the model’s performance does not meet expectations, the adjustable part does not like ‘Kaldi’ have so many different state. Therefore, it’s crucial to ensure that training data is abundant enough before considering the use of an End-to-End architecture.


National Yang Ming Chiao Tung University, Speech AI Research Center(SARC) (July 2023 - March 2024)
- Large Language Model
- Data Preprocessing
- Ubuntu Server Maintain
- GitLab Maintain
Cooperate with TAIDE
TAIDE project, led by prominent academics such as Professor Tsai Tsung-Han from National Central University and Professor Lee Hung-yi from National Taiwan University, is a National Science Council(國科會) initiative.
TAIDE aims to develop a ChatGPT specifically tailored for Taiwan.
SARC undertook the task of localizing and adapting the TAIDE model. Collaboration began in September 2023, and by November 2023, the TAIDE model was adapted for Taiwanese languages, including Taiwanese and Hakka. Simultaneously, it was deployed onto the TAIDE public testing platform for use by the TAIDE team and its partners.
See More About TAIDE


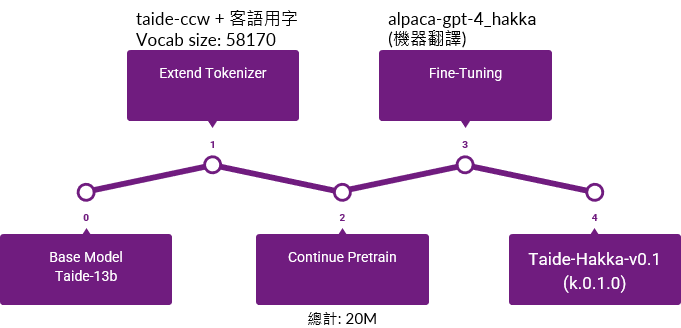
Below are the detailed steps for modeling a Large Language Model (LLM):
- Selecting the Base Model: llama-2, gemma.
- Extend Tokenizer: As the base model lacks knowledge of any specific target language, optimize the Tokenizer for the target language to improve performance.
- Continue Pretrain: At this stage, since the base model lacks knowledge of the target language, expose the model to a large corpus of text in the target language. This helps in cultivating a sense of the new language within the model.
- Fine-Tuning: Once the model becomes familiar with the new language, train it on how to respond to questions posed in the target language. Input a large volume of question-answer pairs to train the model to respond to various queries effectively.
- Output Model.
Cooperate with PHISON (aiDAPTIV+)
Maintaining WorkStation Machines
- Managing all users and their permissions on the server.
- Maintaining the software system environment of the server, including installing updates, patches, and necessary software.
- Ensuring the hardware of the server is functioning optimally by monitoring performance,
- Configuring the server’s network environment, including setting up network connections, firewall configurations. Additionally, setting up Network-Attached Storage (NAS) devices for data storage and sharing.
DLink AI Engineer (6/11~now)
- Speech Recognition
- Large Language Model
- Machine Translator
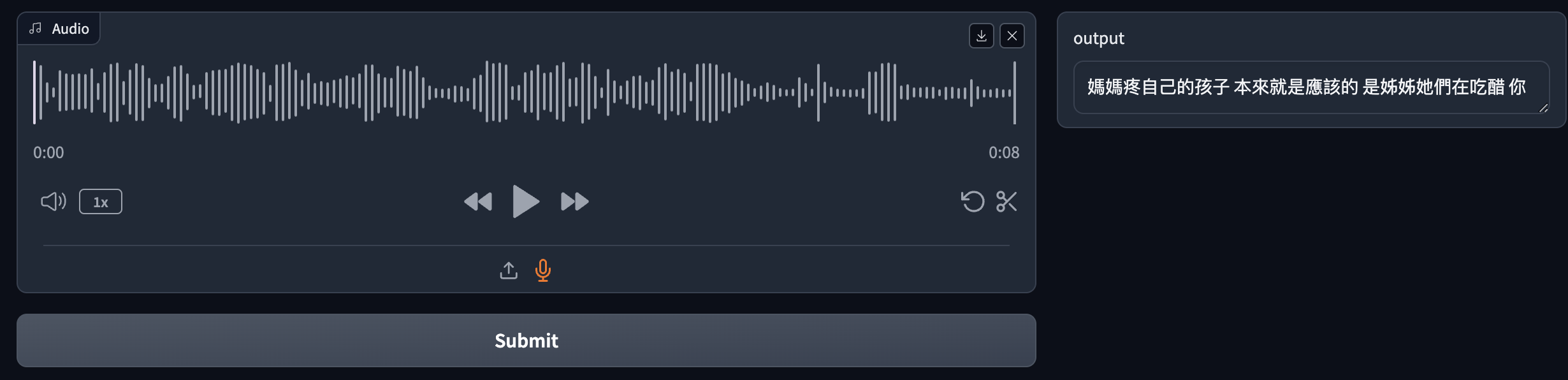
Mandarin & Taigi Whisper Fine-Tune (6/11~7/12)
Collect audios with no precise label from YouTube and Dictionary.
Full Fine-Tune with about 800 hours corpus (non proof data).
Character Correction Rate(CCR) approximately 74%, and it could be better by expand training data.
LLM Evaluation (7/12~7/30)
Build Ollama services platform.
Use IFEval to evaluate LLM’s instruction following score.
You can also refer this page.

Retrieval-Augmented Generation (7/30~now)
Using RAG & Prompt Engineering to customize LLM.
Let non fine-tune LLM, fit to a Calendar Searcher, then summary it.
