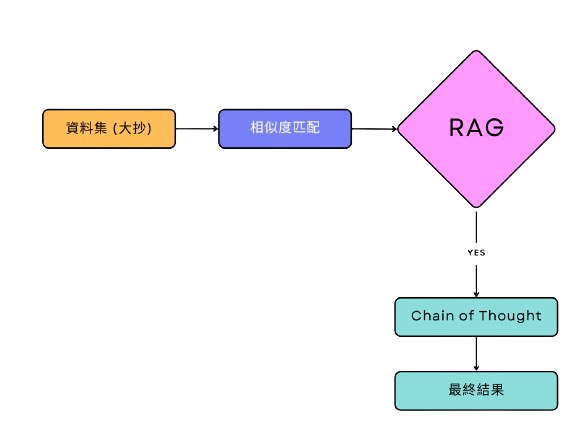
# Kernel generate tool from langchain_community.llms import Ollama
# For streaming output from langchain.callbacks.streaming_stdout import ( StreamingStdOutCallbackHandler ) from langchain.callbacks.manager import CallbackManager callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# langchain chainer from langchain.chains import LLMChain from langchain.prompts import PromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough
# Embedding from langchain_community.embeddings import HuggingFaceEmbeddings
# RAG from langchain_chroma import Chroma from langchain.chains import RetrievalQA from langchain_community.document_loaders import CSVLoader from langchain_community.document_loaders import JSONLoader from langchain.text_splitter import RecursiveCharacterTextSplitter
# Embedding from langchain_community.embeddings import HuggingFaceEmbeddings
# utils import shutil, os import json
if os.path.isdir('./db'): shutil.rmtree('./db')
# load json data loader = JSONLoader(file_path="data/RAG_data.json", jq_schema=".", text_content=False) data = loader.load()
# load csv data # loader = CSVLoader(file_path="data/test.csv", encoding='utf8') # data = loader.load()
# split data for batch embedding text_splitter = RecursiveCharacterTextSplitter( separators=["}"], chunk_size=100, chunk_overlap=0 ) data = text_splitter.split_documents(data)