
將 bit 讀下來並做0、1互換
由於讀取時是從尾端讀取,最後計算答案時是要從後往前回推
1 | class Solution: |
將 bit 讀下來並做0、1互換
由於讀取時是從尾端讀取,最後計算答案時是要從後往前回推
1 | class Solution: |
檢索增強生成(Retrieval-Augmented Generation, RAG)是一種結合了搜尋檢索和生成能力的自然語言處理架構。透過這個架構,模型可以從外部知識庫搜尋相關信息,然後使用這些信息來生成回應或完成特定的NLP任務。
更通俗一點的說,RAG就像考試時教授允許大家帶的A4大抄,你可以在考試的時候邊看邊回答問題。
RAG的運作流程如下圖
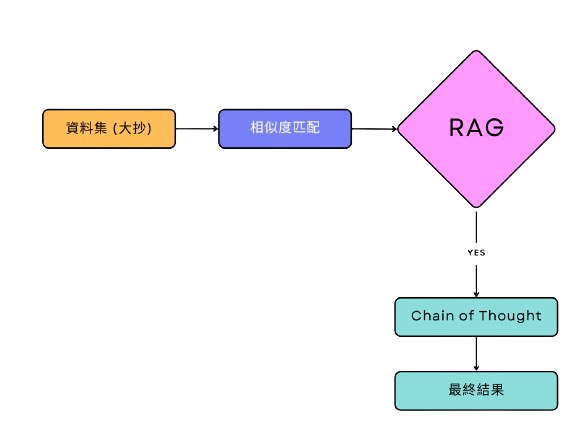
當中的 「相似度匹配」,近乎是RAG技術的核心
我們在大抄裡面優先問題的答案,最快的方法是:“找到與問題最相關的詞語”。而想要將自然語言進行“相關度匹配”的時候,就要使用到Sentence Transformer這個工具了。
目前我們最常處理自然語言的方法是:利用專用的模型,將自然語言嵌入成向量,也就是Vector Embedding。
這些特別的模型(Sentence Transformer),是專門針對相近語意的資訊進行訓練。最後模型就可以做到:評比兩句話之間語意有多相似,最後再給一個相似程度的分數。
我們要的就是將使用者的問題,利用Sentence Transformer與大抄中內容進行比對。
如果找到了分數夠高的內容,那說明我們在大抄中找到了答案。我們就將這段大抄送給LLM一併進行生成,由此就可以達成擴增外部知識庫的功能了。
取得額外資料後,最後生成的流程可以依照自己的需求重新決定(如 Prompt Parameter…)。
以下用一段簡短的程式碼進行示例
1 | # requirements.txt |
1 | # main.py |
IFEval 是一種專門用於評估模型指令順從度 (instruction following)的指標
測試的題目全部都是根據模型的輸出,以客觀的、可辨識的特徵來觀察,模型是否順從使用者要求的指令(instruction)。
測驗主題包含
關鍵字
語言
輸出長度限制
要求特定內容、格式
以下提供一些實際測驗題目當作範例
| Instruction | Group | Instruction Description |
|---|---|---|
| Keywords | Include Keywords | Include keywords {keyword1}, {keyword2} in your response. |
| Keywords | Forbidden Words | Do not include keywords {forbidden words} in the response. |
| Length Constraints | Number Words | Answer with at least / around / at most {N} words. |
| Detectable Content | Postscript | At the end of your response, please explicitly add a postscript starting with {postscript marker} |
| Detectable Format | JSON Format | Entire output should be wrapped in JSON format. |
| Combination | Two Responses | Give two different responses. Responses and only responses should be separated by 6 asterisk symbols: ******. |
| Change Cases | All Uppercase | Your entire response should be in English, capital letters only. |
| Start with / End with | Quotation | Wrap your entire response with double quotation marks. |
| Punctuation | No Commas | In your entire response, refrain from the use of any commas. |
由這些例子可以看出,IFEval可以作為一個客觀評估模型順從度的指標
給定輸入矩陣,檢查是否有 “小、大、中” 的子集。
1 | class Solution: |
找出所有等差數列的子矩陣數量,子矩陣長度至少為3
1 | class Solution: |